Governed AI that ships in weeks.
For regulated industries where AI needs to be governed, not just capable. We ship in weeks — scoped to the work, not the invoice.
30 minutes. A practitioner answers — no sales reps.
“A massive time saver.”
Working credentials — every one verifiable
3 weeks
Verifiable, click-through credentials — not logos for decoration
Proof
Three weeks from kickoff to independently productive engineers.
3 weeks
from kickoff to independently productive engineers
6+
engineers independently productive — across the enterprise
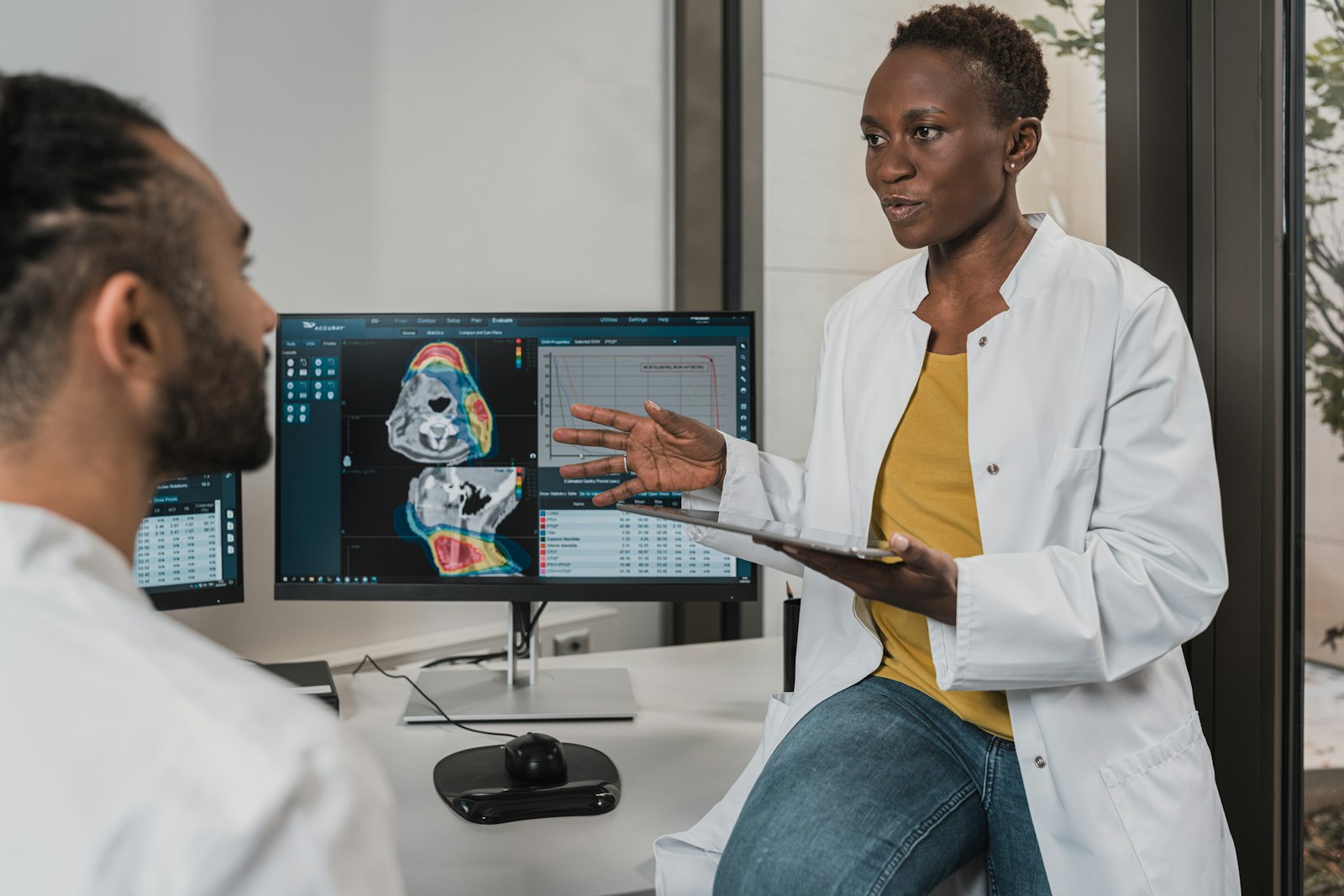
A multi-billion-dollar distribution enterprise — 2,000+ associates · 122 locations — needed its engineering teams productive with Claude Code. Incumbents quoted 12–16 weeks. Kriv AI delivered in three weeks — documented and governed as it went:
- 12 live training sessions
- 26 training documents
- 5 role-specific starter kits
- 6+ engineers independently productive
“A massive time saver.”
What we do
Governed AI services. One discipline.
All 23+ servicesKriv AI builds, teaches, and operates governed AI for regulated industries — from readiness assessments and agentic automation to LLM fine-tuning, MLOps, and compliance-as-a-service. Every service line ships with the same discipline: scoped, logged, and reviewable by design, with 56 live AWS Marketplace listings to procure through.

How we work
Five chapters. Every one leaves an artifact.
Assess
We map your data, risk posture, and the work AI should actually do — no slideware, just findings.
→ Readiness & governance assessment report
Govern
Access scoping, request logging, and review gates designed before the first model call.
→ Governance framework & policy pack
Build
A small senior team ships the pilot inside your environment, with your engineers beside us.
→ Working system + role-specific starter kits
Validate
Evaluation runs, red-team passes, and sign-off documentation your compliance team can defend.
→ Evaluation logs & validation dossier
Operate
We hand over or run it as a service — either way, the audit trail keeps writing itself.
→ Runbooks & operating documentation
Not ready for a project? Start smaller.
A free 30-minute AI readiness check.
Bring one workflow you suspect AI could improve. You leave with a straight read on whether it is worth building, what governance it would need, and what it would roughly take — whether or not you ever hire us.
A practitioner answers — no sales reps.

Who we serve
Healthcare, where governed isn't optional.
Clinical and operational AI lives or dies on trust. We build assistants and pipelines that respect roles, log every request, and answer with sources — so your compliance team signs off without holding their breath.
- HIPAA-aligned delivery with BAA available
- Access scoped to role before the model ever answers
- Evaluation gates and documentation built for audit day
And beyond
Insurance, finance, and the serious mid-market.
Regulated doesn't have to mean slow. For payers, financial teams, and mid-market operators, we deliver the same governed build discipline at a size and price that makes sense — weeks to value, not quarters.
- Claims, audit, and member-operations automation with owners and logs
- NIST AI RMF-aligned delivery, documented as we go
- Senior practitioners only — the people you meet do the work

The buying committee
Whoever you are in the room, start here.
Enterprise AI decisions move through six to ten people. Kriv AI writes a briefing for each of the three who can veto it — so your whole committee reads from the same facts.
Governance & trust
Evidence, not promises.
Every claim on this site clicks through to its source — marketplace listings, partner registries, government databases. The same standard applies to the systems we build for you: scoped, logged, and reviewable by design.
What governed means
From the journal
Field notes from regulated AI work.
Browse all field notes
What we're building
The pipeline — live, in progress, and coming next.
Claude Code Training — full program page
Complete service page: curriculum, proof section, pricing, and AWS Marketplace procurement link.
Case studies
Individual engagement write-ups across healthcare, insurance, and finance — real names where permitted.
Partner portal
Self-service hub for referral partners, white-label delivery partners, and resellers.
Straight answers
Straight answers to the questions buyers actually ask.
What does "governed AI" actually mean?
Governed AI means every system Kriv AI ships is scoped, logged, and reviewable by design: a named owner for every agent action, audit trails for every step, and delivery aligned to the NIST AI Risk Management Framework. It is the difference between AI your compliance team can defend in an audit and AI they have to apologize for.
What makes Kriv AI different from larger AI consultancies?
Right-sizing. Large firms deploy pyramid structures — project managers, business analysts, junior consultants, and engagement leads all billing to the same project. Kriv AI sends a senior practitioner who both scopes and delivers: no handoffs, no bench, no discovery theater. The same scope that a large consultancy quoted at $400K+ and 12–16 weeks, Kriv AI delivered in three weeks. That gap is structural, not exceptional.
What does "HIPAA-aligned, BAA available" mean?
It means Kriv AI designs delivery around HIPAA's safeguards — data minimization, access controls, audit trails — and will sign a Business Associate Agreement for engagements that touch PHI. It is deliberately not a certification badge: HIPAA has no official certifying body, so vendors claiming "HIPAA certified" are overstating. We state exactly what we do.
How can delivery take 3 weeks when others quote 12–16?
Because the scope is honest and the delivery is direct. Kriv AI's flagship engagement took a 2,000+ associate, 122-location enterprise from kickoff to independently productive engineers in 3 weeks: 12 live training sessions, 26 training documents, and 5 role-specific starter kits, delivered by the same practitioner who scoped the work — no handoffs, no bench.
Can we buy through AWS Marketplace?
Yes. Kriv AI maintains 56 live professional-services listings on AWS Marketplace, so you can procure through your existing AWS account and apply existing cloud spend commitments — usually skipping net-new vendor onboarding entirely. Every listing is public and verifiable on our AWS Marketplace seller profile.
Start here
Governed AI that ships in weeks. Yours could be next.
A 30-minute discovery call with the person who will actually do the work — not a sales rep with a deck.
+1-732-433-5564 · info@kriv.ai · East Brunswick, NJ
“A massive time saver.”
Flagship engagement, 2025 — 2,000+ associates · 122 locations. From kickoff to independently productive engineers in 3 weeks.
Continue the chapter
Claude Code training — engineers independent in 3 weeks
The flagship program: 12 sessions, 26 documents, 5 role-specific starter kits.
The credential ledger — every line verifies
AWS Marketplace (56 listings), Claude Partner Network, Databricks, Microsoft.
Government & public sector — registrations verbatim
SAM.gov registered, NJ SBE approved, NAICS codes stated plainly.